
Engineering Insights is an ongoing blog series that gives a behind-the-scenes look into the technical challenges, lessons and advances that help our customers protect people and defend data every day. Each post is a firsthand account by one of our engineers about the process that led up to a Proofpoint innovation.
Proofpoint Enterprise Archive offers a central, searchable repository that allows ingestion and meets Financial Industry Regulatory Authority (FINRA) standards for compliance. This blog explores how we achieved scale using Kubernetes as our deployment platform.
Kubernetes and Horizontal Pod Autoscaler (HPA)
Kubernetes is an open-source platform that provides straightforward container orchestration, scalability, resilience and fault tolerance for microservices. All of these factors made it a clear choice as a deployment platform for our application.
HPA in Kubernetes is a built-in feature that automatically adjusts the number of replicas (pods) of a deployment based on observed metrics. In a regular environment, HPA queries the Kubernetes metric server, calculates the intended number of replicas and updates a deployment with a desired replica count. The deployment scales the pod count to the desired value.
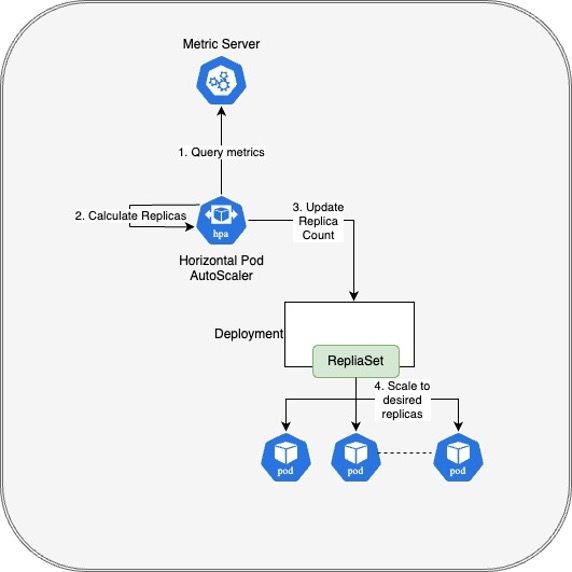
Horizontal Pod Autoscaler (HPA) in Kubernetes.
Scaling a deployment based on custom metrics
Autoscaling solutions are typically based on runtime metrics like CPU load. However, built-in system metrics are not always adequate for making autoscaling decisions. You need custom metrics to make useful autoscaling decisions.
The Proofpoint Enterprise Archive includes a task scheduling system that takes tasks from the queue and executes them one by one. CPU-based autoscaling might not be optimal here because:
- Tasks can be IO-bound, not CPU-bound
- Tasks can have priorities, schedules and deadlines
- For prolonged periods, NO tasks might be scheduled to run at all; in this case, the scaling solution ideally would downscale to zero pods
Another applicable scenario would be to scale proactively based on an artificial intelligence (AI) system that predicts load based on past usage patterns.
For our use case, the tasks queue length can be a better metric to make scaling decisions, but it requires a custom queue length metric.
Although you can set up Kubernetes HPA for this type of scaling, it can be challenging to implement custom metrics for scaling. Furthermore, HPA does not support scaling down to zero pods, which is essential to manage costs.
Kubernetes Event Driven Autoscaling (KEDA) is a complementary autoscaling technology you can integrate into HPA. It offers a wide variety of scalers that can fetch metrics from various sources, including Prometheus monitors. KEDA uses these metrics for its integration with Kubernetes HPA.
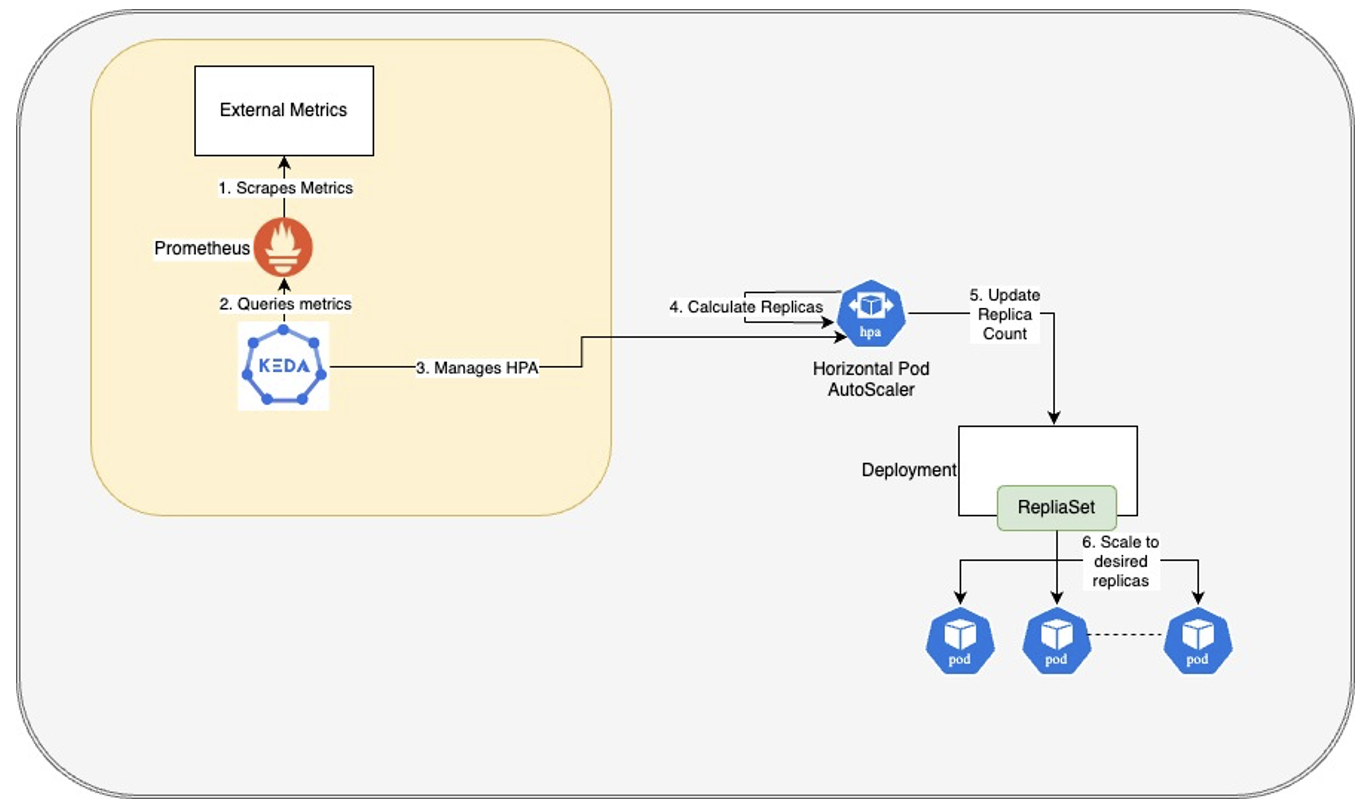
KEDA using its Prometheus Scaler to query metrics from Prometheus.
The diagram above shows KEDA using its Prometheus Scaler to query metrics from Prometheus. In our system, the external metrics are mostly exposed by the application itself. KEDA uses these metrics to manage the HPA thereby indirectly controlling the pods’ replica count.
KEDA also allows scaling the pods to zero by simply deleting the HPA object. When metrics demand the creation of pods, KEDA recreates the HPA object and starts to manage it.
Sample definition and scaling behavior of a processor
As a scaling example, we will show a background task processor (BTP) that waits for customer-driven events, picks them up and processes them. It is idle when there are no events to process.
Our application exposes metrics that signal when and how many processors are required to handle customer events at any given time. Prometheus scrapes these metrics and makes them available to KEDA for processing.
KEDA scale definition

The above KEDA query definition includes the following parameters:
- btp_scaling_metrics is the Prometheus metric for scaling
- ActivationThreshold is the threshold to starting scaling
- Threshold indicates there should be one scaling activity every fifth metric value
- StabilizationWindowSeconds allows setting the safest (largest) “desiredReplicas” number during the last N seconds
- Fallback settings specify what to do if there is Prometheus connection failure
Another parameter, scaleTargetRef, configures the target resource for scaling. Acceptable values are Deployment, StatefulSet or Custom Resource (like ArgoRollout object). In this example, scaleTargetRef is a Kubernetes deployment object.
The detailed definition specification can be found here.
Scaling up detection
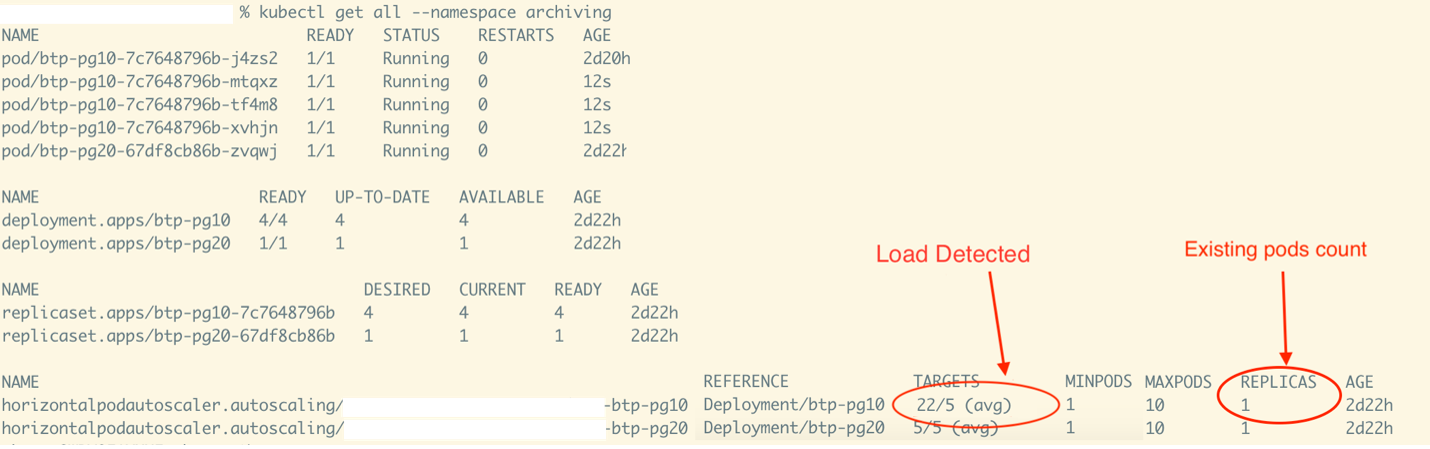
Detection of needing scaling up activity.
The activity snapshot above shows that the need for a scaling up activity has been detected. The external btp-pg10 metric received by KEDA is 22 against the configured threshold of five. Since there is only one pod running, it must handle all the load for now.
Since a pod’s processing capacity is set to a goal of less than or equal to five, four more pods are needed to handle a metrics load of 22 without overloading any of the pods. A scaling activity takes place to add four more pods to the deployment.
Scaling up
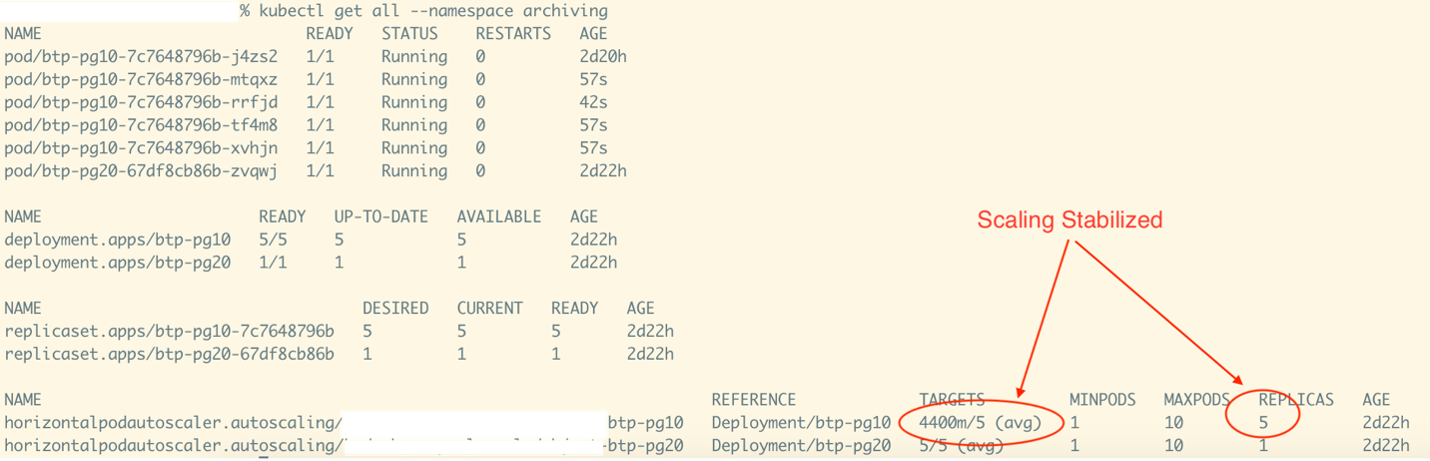
Post scaling, running 5 pods.
The activity snapshot above shows that there are now five running pods after scaling. The metrics load of 22 is distributed among five pods, resulting in a load of 4.4 (i.e., 4400m) per pod.
Since the TARGET = Load Per Pod/ Threshold, the value reached is 4400m/5, and no more scaling activity is needed.
Scaling down detection
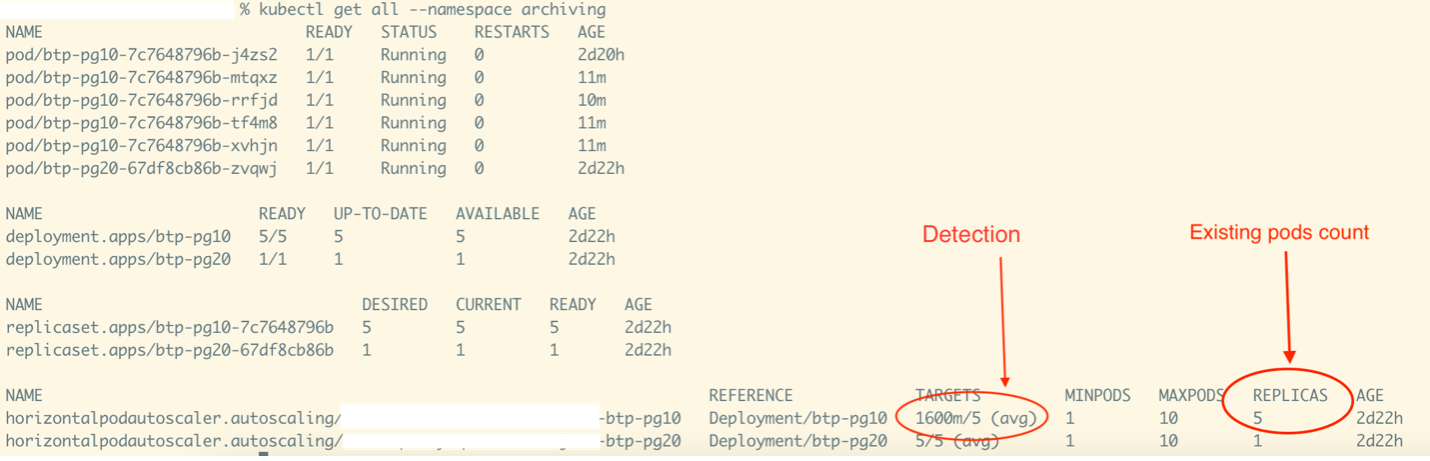
Detection of needing a scale down activity.
The activity snapshot depicts the detection of the need for scale down activity. The metrics value, not captured in this snapshot, was eight. Since there were five running pods, the load per pod is 8/5 = 1.6 (or 1600m, as shown).
Given the “TARGET” (Load Per Pod/ Threshold), this equates to a value of 1600m/5. (Note that the five used here is the threshold and not replicas count.)
Since each pod has a metrics-handling threshold capacity of five, two pods would provide sufficient capacity (2*5 =10, which is enough to handle a metrics load capacity of eight). This signals a scaling down activity in the deployment.
Scaling down

Active scaling down event with pods terminating.
The activity snapshot above shows an active scaling down event with pods terminating. This is a continuation of the previous event. A total of three pods are being destroyed because, as discussed earlier, two pods are sufficient to handle the metrics load of eight.
The above example demonstrates how KEDA creates and manages the Kubernetes HPA object for scaling, abstracting the complexity of direct HPA object creation by the developer.
Final thoughts
Kubernetes is a highly flexible system that provides powerful tools for container orchestration, scalability and the management of distributed applications. However, its complexity requires users to invest time in learning its concepts and best practices to use its capabilities effectively.
The use of Kubernetes third-party complementary technologies like KEDA can significantly enhance a Kubernetes deployment by providing additional functionality, simplifying management tasks, improving security and extending compatibility with other systems. That, in turn, allows users to focus more on business rules.
The integration of Kubernetes into the Proofpoint Enterprise Archive has allowed for cost-effective scaling and efficient deployment management of systems.
Join the team
At Proofpoint, our people—and the diversity of their lived experiences and backgrounds—are the driving force behind our success. We have a passion for protecting people, data and brands from today’s advanced threats and compliance risks.
We hire the best people in the business to:
- Build and enhance our proven security platform
- Blend innovation and speed in a constantly evolving cloud architecture
- Analyze new threats and offer deep insight through data-driven intelligence
- Collaborate with our customers to help solve their toughest cybersecurity challenges
If you’re interested in learning more about career opportunities at Proofpoint, visit the careers page.
About the author

Sumit Kumar is a staff engineer at Proofpoint who works on the Archiving Infrastructure Team. Committed to providing simple solutions for challenging problems, Sumit has been helping to build the platform needed to support the next generation archiving solution from Proofpoint. In his free time, Sumit enjoys being with his family and playing and getting into trouble with his kids.
